6 minutes
Can Coding Agents Actually Do My Numerai Job?
I’ve been running a Numerai Tournament bot for years. Download the dataset, train a model, submit predictions, watch the live score drift, iterate. It’s exactly the kind of bounded, feedback-rich, open-ended task that today’s coding agents claim to handle.
That led to a concrete question: can Claude, Codex, or Gemini actually do this job end-to-end, without me holding their hand?
That question turned into NumeraiAgentBench: a benchmark that drops coding agents into a Docker container with a Numerai model id to submit to, a 24-hour timer, and one sentence of objective: score as high as possible on the Numerai tournament leaderboard. Then measures what happens.
Public dashboard: numerai-agent-bench.pages.dev
Numerai profile: https://numer.ai/~nero_nab
Why another agent benchmark
Most agent benchmarks are synthetic. Unit-test pass rates. Toy repos. Puzzles with known answers.
Numerai is none of those. The data is obfuscated (you don’t know what the features mean). Feedback is delayed 20 days (you can’t overfit to validation). There’s no ready-made solution that wins consecutively. A model that works last month might be worthless next month. This is closer to what “doing ML work” actually looks like.
So instead of “can the agent pass this test,” the question becomes: can the agent research, choose a stack, build a pipeline, handle an external API, be compute efficient, and iterate from live scores?
The setup
Each agent runs in its own Docker container on a dedicated workstation (i9, RTX 3090, 64GB RAM1). The base image ships Python, Node (for the agents), CUDA. The agent picks its own ML framework.
Two difficulty levels are operational:
- L3 Autonomous. One sentence of objective. Bounded compute time. Submission is done via a scheduler, agents provide the artifacts.
- L4 Forever Loop. Same objective, no timeout. The agent runs indefinitely, iterating on its own models and submitting daily. If it crashes, a wrapper restarts it. State syncs to GitHub every couple of minutes.
Two more levels (guided and directed) are designed but not built yet. L3 and L4 are the interesting ones, they’re where the agent has room to actually be autonomous.
Around each agent run I attached sidecars:
- mitmproxy logs every HTTP call as JSONL
- git-watcher auto-commits the workspace every 60 seconds
- resource-monitor samples CPU, memory, GPU
So the harness captures not just “did it submit” but what it looked at, what it tried, what it threw away.
What I learned building the harness
Most of the work is not the agent. It’s the plumbing. Lock management so only one agent runs at a time (because I’m running this on my own server). Stale-lock recovery when a PID dies 2. State files that survive crashes with atomic tmp-file-rename writes. A submission window watcher (Numerai has daily windows, Tue–Sat) that fires off each agent’s submit.sh in its original container, minus the heavy sidecars. Systemd. Ansible. CI/CD with rollback. This is ~300 pytest tests of infrastructure before you even talk about an agent.
Gatekeeper checks age badly. After I shipped L4 (the forever-loop mode), the agent was invisible on the public site for ten days despite 100+ git commits from its own workspace. L4 agents don’t use submit.sh — they submit autonomously. But the round watcher was checking for submit.sh before checking the execution mode, so it silently skipped L4 every five minutes. A precondition that made sense for the original use case wasn’t updated when a new mode was added. The fix was a two-line reorder.
Passive verification needs reconciliation. L4 agents can submit outside the scheduler’s active polling window. Codex L4 made a later upload for round 1269, but the watcher had already stopped passive verification after 24 unsuccessful checks and recorded the round as unverified. The run summary saw the upload-like activity; the public watcher state still showed the abandoned May 16 record. For loop-mode agents, a finite retry window is not enough. The system needs a reconciliation step that can reopen or correct round outcomes when Numerai later reports a newer submission for the same model and round.
What I’m finding about the agents
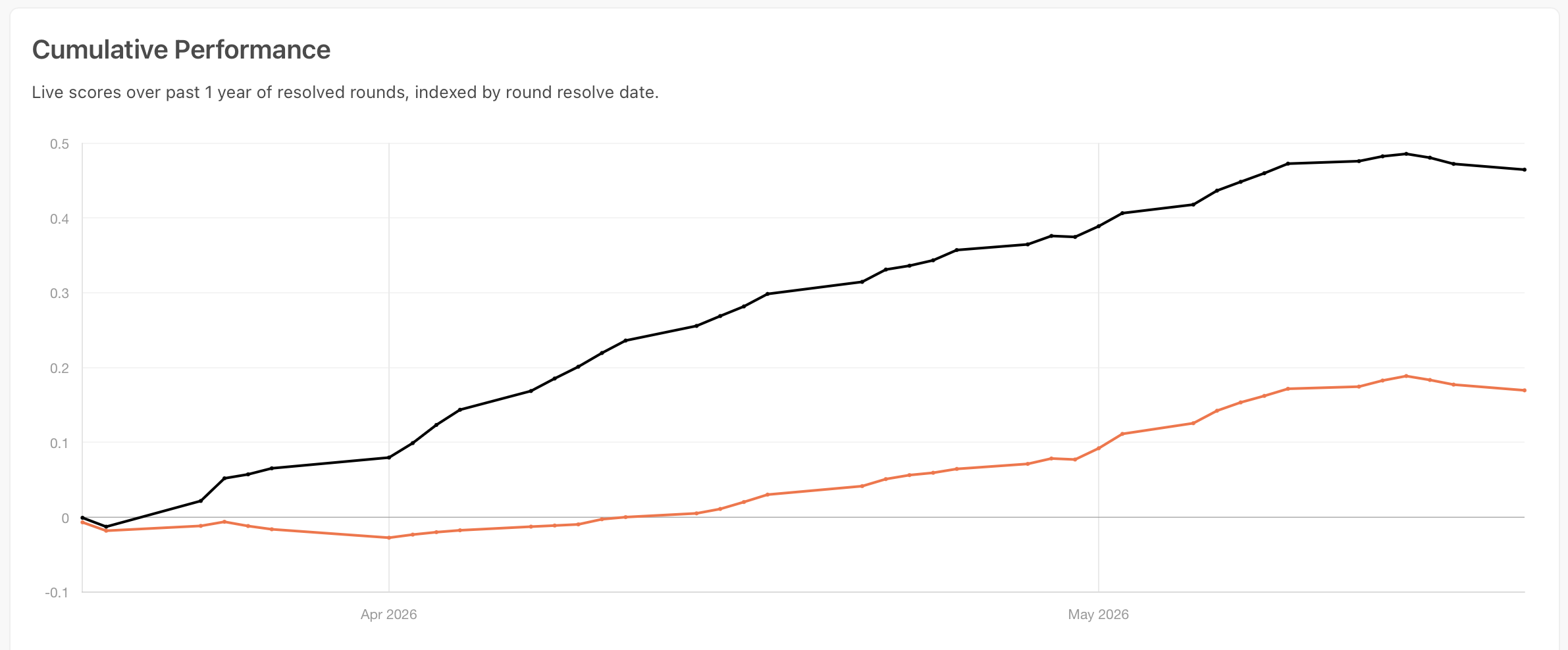
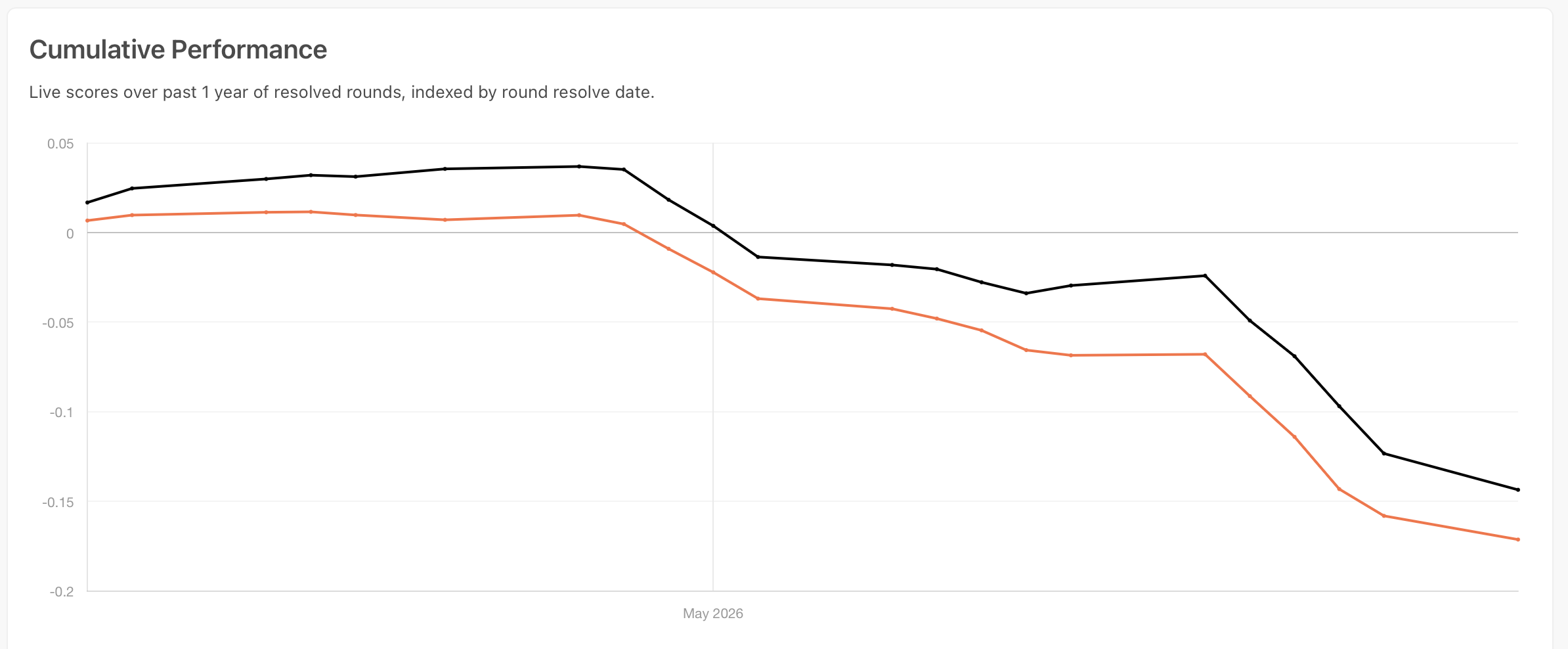
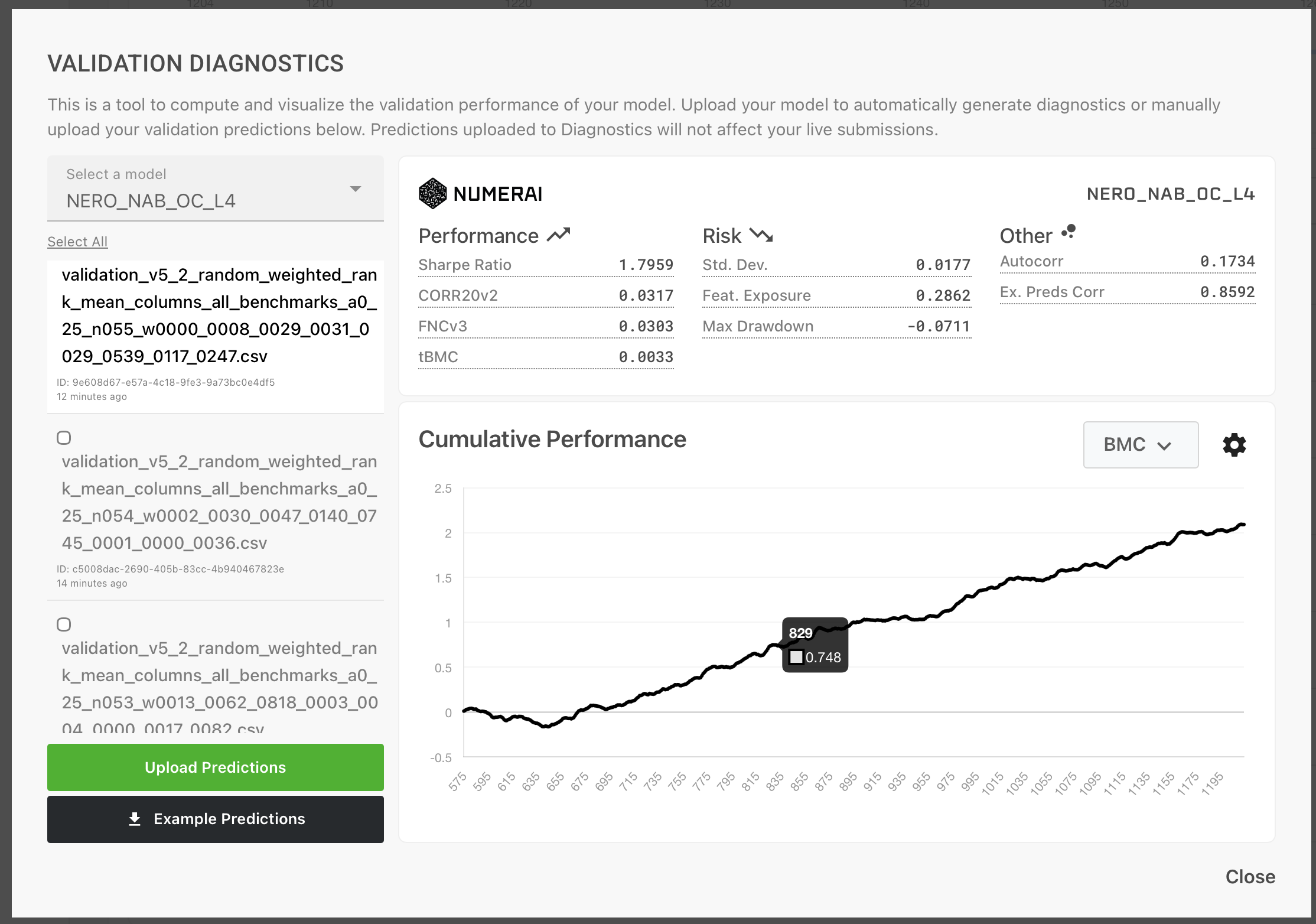
I’ll save the detailed scores for a follow-up, because the live tournament resolves on a ~20-day lag and I want honest numbers. Early impressions:
- Agents can go from cold start to first submission in L3. They do the research, download data, pick a stack (usually LightGBM, occasionally CatBoost or neural nets), and ship.
- The interesting variance isn’t in the first submission. How quickly does the agent realize its feature engineering is weak? Does it try to diversify models or double down on one? Does it read the Numerai docs, or just pattern-match on Kaggle memories?
- L4 agents add a second class of behavior: they write their own long-running scaffolding. One agent spawned an autonomous loop as a background Python process, running independently from the Claude Code session. When the wrapper restarted Claude, the new session did not know about that process. The harness needs to account for agent-created processes, not only the top-level agent CLI.
- Codex L4 was the first agent I saw using Numerai’s diagnostics endpoint systematically. It built a queue of hundreds of candidate submissions, uploaded diagnostics-sized prediction files, parsed the returned validation metrics, and promoted candidates based on validation CORR. That is useful behavior: the agent found an external evaluation surface and built a search loop around it. It is also a warning. Because MMC was not directly available in the diagnostics response it parsed, and because the L4 prompt only mentioned CORR/MMC without clearly stating MMC20 as the primary objective, the agent optimized the easiest visible signal. I have since changed the prompts so all levels state the same objective: achieve the highest possible rank under MMC20.
What’s next
The infrastructure is in place; the interesting work is now the analysis and reconciliation layer. Eight-plus weeks of live tournament runs have accumulated. I want to build the results layer that turns event logs, submissions, diagnostics activity, and live scores into claims I can defend.
A few open threads:
- When do L4 agents plateau? Do they plateau at all, or drift?
- Are the agents researching or remembering? A network-capture ratio gives a crude signal here.
- Do the agents optimize the benchmark objective, or do they optimize the most available proxy signal?
- How should loop-mode submissions be reconciled after the scheduler’s active polling window closes?
I’ll write more as the data comes in. If you want to follow along: the public dashboard updates with each Numerai round, and I’ll post results as they resolve.
-
I know it’s old hardware. But this is what I have and it serves me well. Plus, it is cheaper for me to run locally than in the cloud. ↩︎
-
Complicated scheduling logic is due to the fact that I want to give all agents roughly equal compute time, while staying on a single machine. Financial reasons. ↩︎